アイスタイルデータコンサルティング株式会社
- TOP
- CASE STUDIES
- アイスタイルデータコンサルティング株式会社
@cosmeの膨大なデータを「言葉」で操る。アイスタイルが挑んだ生成AIによるデータ分析革命

(左から金、小暮、押野氏)
日本最大級の美容プラットフォーム「@cosme」を運営する株式会社アイスタイル。同社が保有する膨大な美容データを、より迅速かつ深くクライアント支援に活用するため、生成AI(LLM)を用いたデータ抽出・分析プロジェクトが始動しました。Treasure DataのAI Foundryを活用した先進的な取り組みについて、プロジェクトを牽引した3名にお話を伺いました。
【Profile】
株式会社アイスタイル
押野 卓也 / アイスタイルデータコンサルティング株式会社 副社長
ISDC側でデータ活用を推進。本プロジェクトではプロジェクトオーナー兼リーダーを担当。
HiveIQ
小暮 和基 / COO&Marketing Consultant
本プロジェクトでは、プロジェクトマネジメントを担当。
金 氣範 (Kibum Kim) / Chief AI Officer
本プロジェクトでは、生成AI関連の技術リードとしてプロンプト設計、ロジック構築を担当。
プロジェクト概要・背景
―― まず、今回の取り組みを始めた背景について教えてください。
押野:最大の目的は、アイスタイルが保有する日本最大級の美容データを、クライアント支援において「もっと高速に」「もっと深く」活用することでした。

アイスタイルデータコンサルティング株式会社では、@cosmeの会員データをはじめ、アイスタイルが保有する国内最大級の美容データベースを用いた化粧品メーカー様の課題解決に寄り添いデータの力で伴走する「B2B」コンサルティング事業を行っております。
日々の業務では、ユーザーのクチコミや評価と言った「定性データ」や閲覧履歴や購買データなどの「定量データ」を掛け合わせ戦略的な示唆を見出すことが至上命題です。
しかしながら、従来のプロセスではデータ抽出業務におけるエンジニア依存がボトルネックとなり、ビジネス側が”もっと分析したいのにできない”という機会損失が発生していました。
Treasure Data の LLM 機能を活用することで、「コンサル自身でデータ分析を完結できる世界」 を実現できれば、組織全体の分析力を一段引き上げ、事業インパクトを大きく高められると考えたのです。そうした狙いから本プロジェクトがスタートしました。
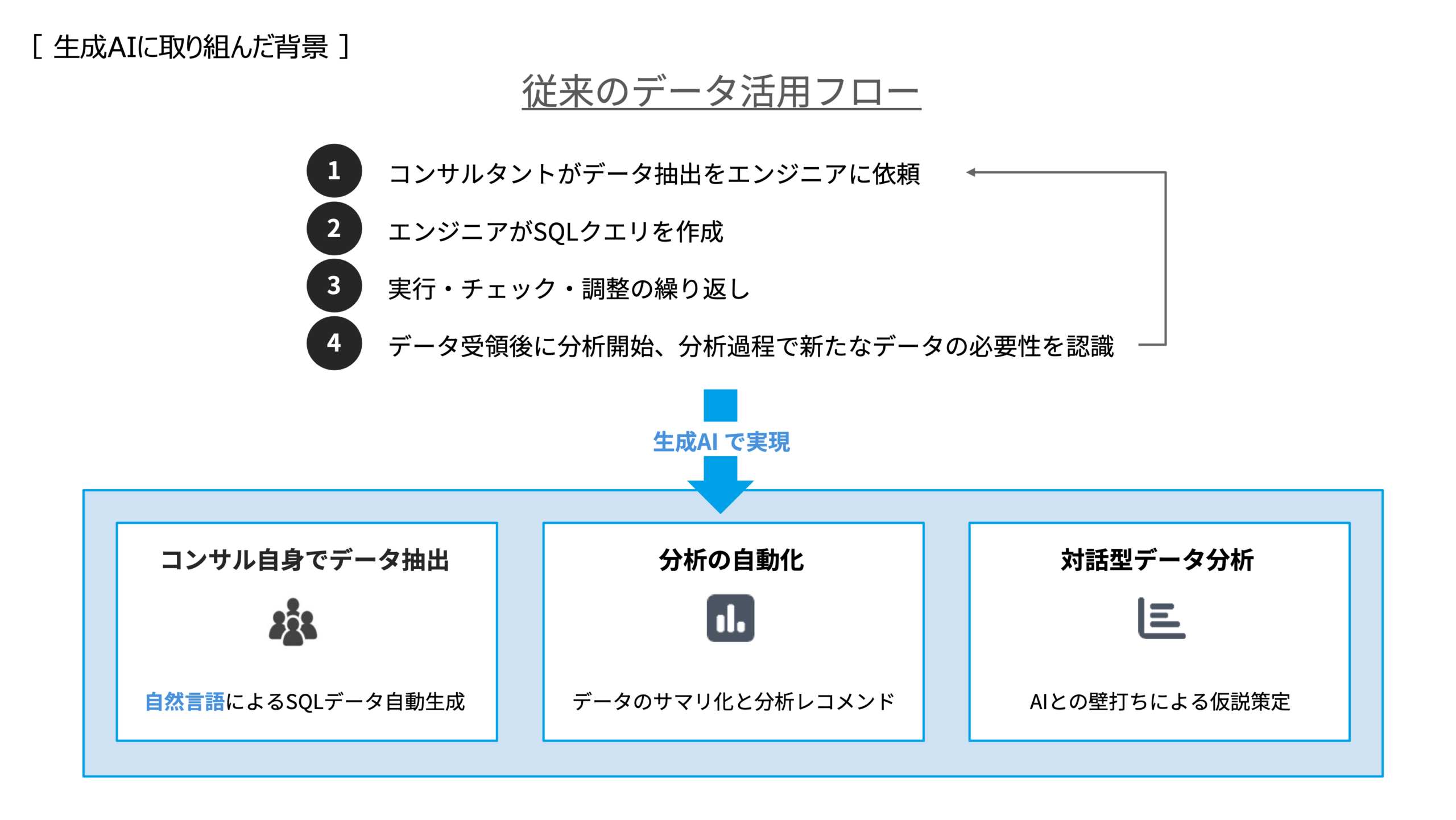
―― 単なる効率化以上の狙いがあったのですね。進める上での課題はどのような点でしたか?
押野:@cosmeのデータは市場でも類を見ないほど多層的です。カテゴリ階層や年齢基準など、独自のビジネスルールが複雑に絡み合っています。例えば、アイスタイルが運営しているWebサービスには@cosmeと@cosme SHOPPING(EC)があり、それぞれページネーションが異なるアクセスログが存在します。
これらの複雑なデータを、LLMがいかに正しく解釈し、迷わず現場で使える形に落とし込めるかが大きな挑戦でした。
プロジェクト体制
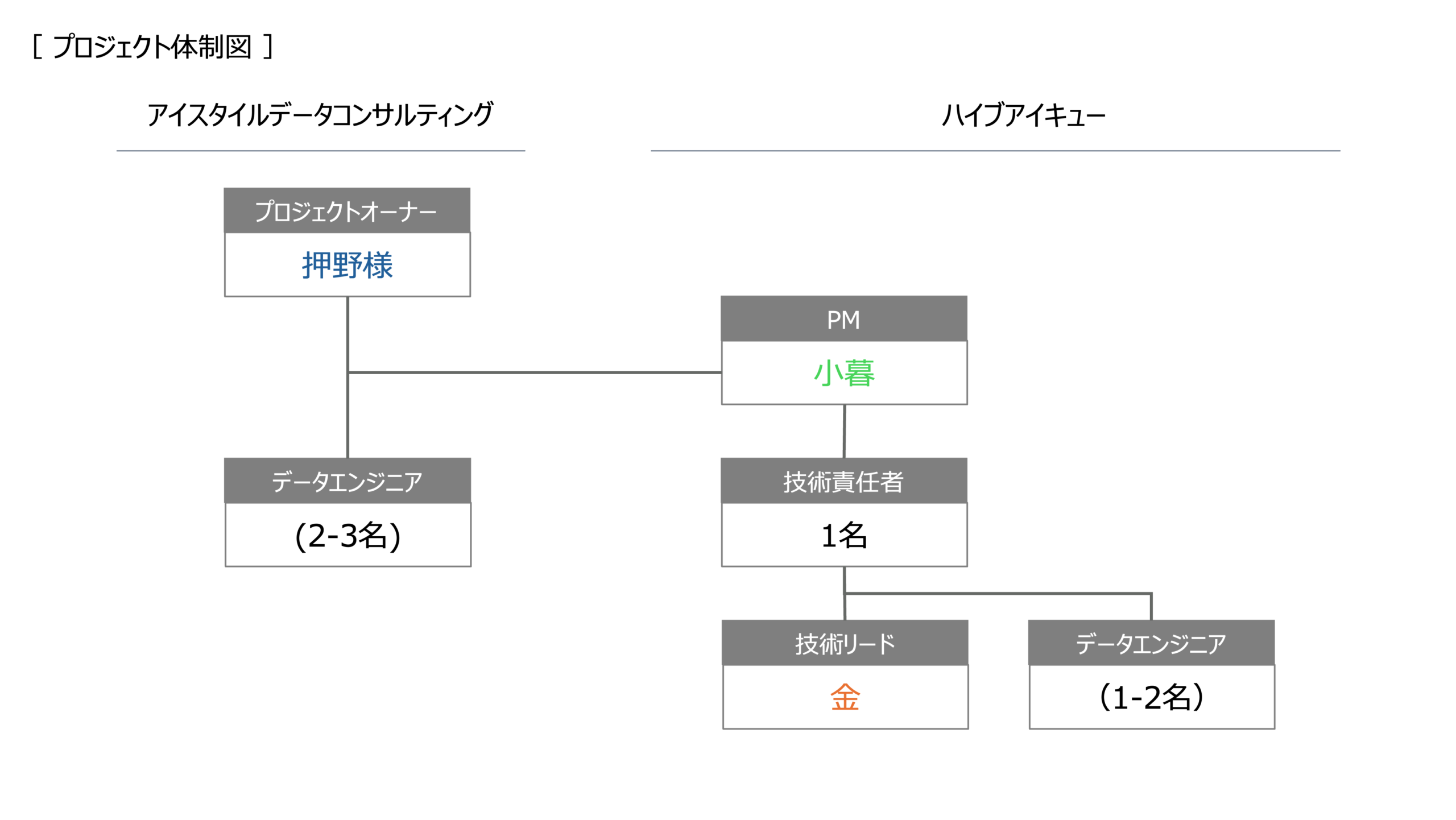
―― プロジェクトはどのような体制で進められたのでしょうか。
押野:私がプロジェクトオーナー兼リーダーを務め、社内のエンジニアチームと共に進めました。パートナーとしてHiveIQさんに入っていただき、小暮さんにはPM的な立ち回りを、キムさんには技術的な実装をご担当いただきました。
小暮:今回はTreasure Dataの「AI Foundry」を活用したのですが、機能自体がリリースされたばかりで、アイスタイル様にとっても弊社にとっても初めて取り扱うものでした。普段のプロジェクトよりも一層アジャイル的な進め方を意識し、実装の進捗共有やアウトプットの品質確認などは密に連携を取りながら進めました。
―― 実際にはどのようなプロセスで進められたのでしょうか。
小暮:大きくわけて3つのフェーズがありました。
最初はα版となる初期エージェントを開発したフェーズ。アイスタイル様のTreasure Data CDPの環境には、すでにある程度主要なデータが格納されている状態でしたので、まずは既存環境の棚卸しから着手しつつLLM用のデータマート構築を進めました。
ここでは押野さんが仰る通り、データは多層的、かつ類似したデータ構造が複数存在している状態でしたので、それら様々なデータをLLMに正確に解釈・扱わせるための適切なデータマート構築が必要でした。日々生み出されるデータをTreasure Data CDPに取り込み、成型し、そうして作成されたLLM用データマートを元にエージェント設定します。
続いて初期開発されたエージェントからβ版として実用レベルを目指すためにブラッシュアップするフェーズです。
アイスタイル様の現場が普段より実施されている分析やデータ抽出によりフィットするようシステムプロンプトのチューニングやデータマート再整備を徹底的に施しました。このタイミングでは、エージェントに質問や分析を投げかけた際のアウトプット、および処理内容をアイスタイル側メンバー様にも積極的にご協力いただき多数のレビューをいただけたことが開発スピードや品質改善に大きく寄与しました。
プロジェクトを開始してからおよそ半年をかけ、実際にユーザーとなるコンサルタントの方にもお試しいただける本番エージェントのリリースにこぎつけました。それ以降は挙がった課題やフィードバックに対応、追加データを反映させるなど追加アップデートを現在も継続しています。

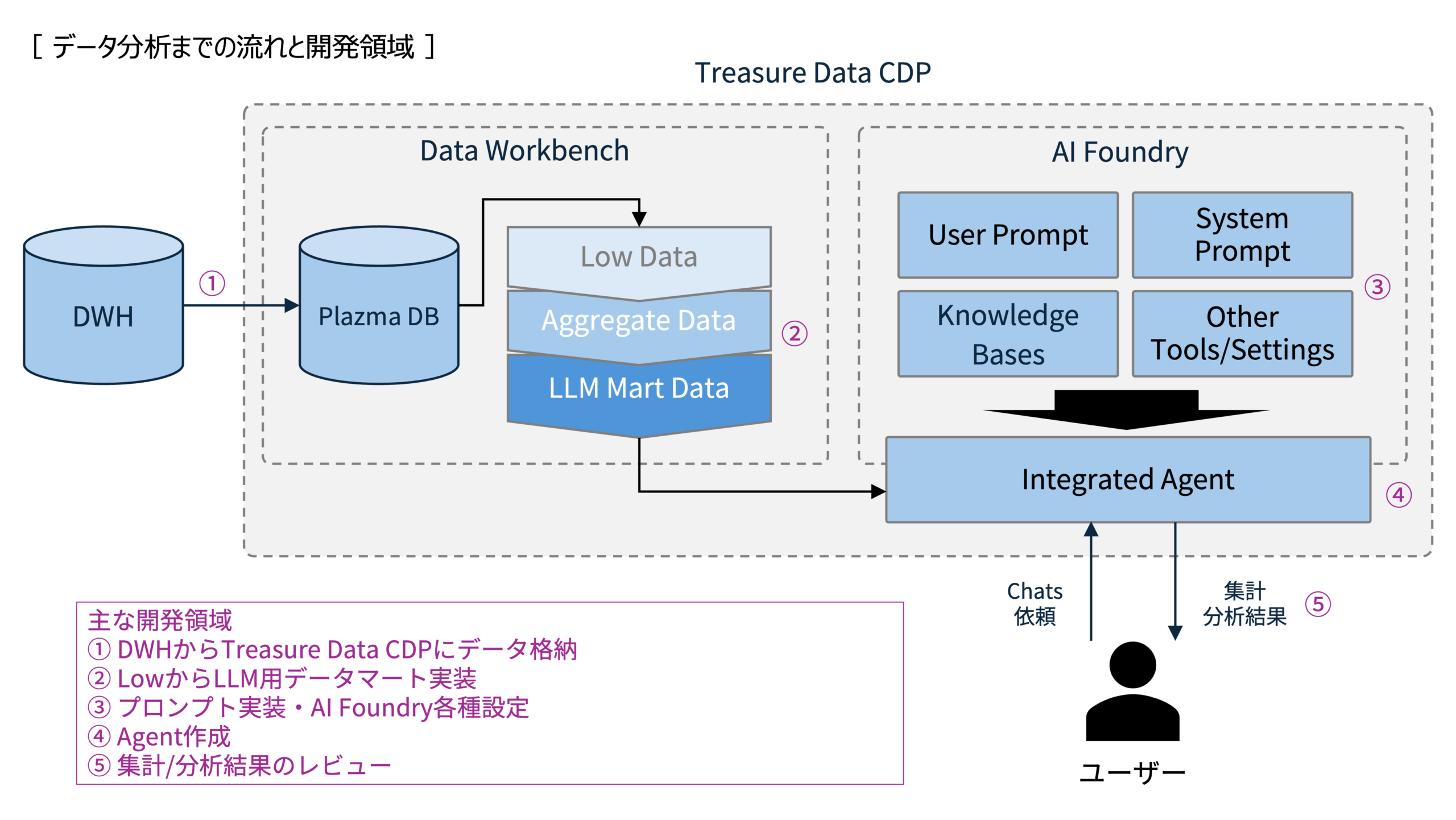
技術的な挑戦
―― 今回のプロジェクトのテーマである「生成AI(LLM)を用いたデータ抽出・分析」について、専門家として特に意識したポイントはどこでしょうか。
キム:「ドメイン知識の注入」と「システム制約」の高度なバランス設計を強く意識しながら進めました。
EC・店舗・アプリに散在するアイスタイル様固有のビジネスロジックは、AIがデータを見るだけでは推論困難な要素が多く存在します。@cosmeのような大規模かつ複雑なデータ構造では、単純にLLMにデータを読ませるだけでは不十分で、ビジネスルールや業務文脈を正確に理解させる必要がありました。
これらを知識ベース等で補完しますが、情報過多はコンテキスト圧迫や応答遅延を招くため、「知識の粒度」と「汎用性」の全体設計に腐心しました。個別対応のパッチワークではなく、全体最適を考慮した堅牢なアーキテクチャの構築こそが最大の難所でした。

加えて今回のプロジェクトは「自然言語でのデータ抽出・分析を行うエージェント」という目的でしたので、自然言語の曖昧さを実行可能なクエリ要件へ落とし込むための「プロセス標準化」も非常に重要な要素でした。
ユーザーは「人気商品を教えて」と直感的に問いかけますが、データ定義上は「期間はいつからいつまでなのか」「どのチャネル(ECなのか店舗なのか)を対象とするのか」「指標はPV数なのか売上なのか購入件数なのか」といった具体的なパラメータが必要になります。
通常のシステム開発では仕様を明確に定義すれば良いのですが、LLMは「賢すぎる」ために、データの粒度や範囲の曖昧さ、初期情報不足などの問題があっても、与えられた情報から勝手に推論してアウトプットを出してしまうのです。この「善意の暴走」をどうコントロールするかが、実務適用の鍵となります。
このギャップを埋めるため、AIが即答せずにまず「要件定義チェックリスト」を提示し、ユーザーと合意形成を行う対話フローをシステム的に強制しました。それ以外にもAIを検索ツールではなく、プロのアナリストと同様の「説明責任」と「確認手順」を遵守するエージェントとして振る舞わせるためのチューニングに腐心しました。
―― 具体的にはどのような課題や工夫があったのでしょうか?
キム:特に開発の初期フェーズにおいては、誤集計が発生したり同じ依頼文なのに異なる回答が返ってきたり、レスポンススピードにバラツキが発生するなどの事象が頻出しました。要因は様々ですが、先ほど話した”LLM側の推測による意図しない判断”に起因する部分が大きいようでした。
そこで、事前に整理した業務ルールを中心に推論するように「強制的な初期化」と「二段階の検証プロセス」を実装しました。
まず、会話開始時に必ずサブエージェントを呼び出し、最新の定義情報をコンテキストに注入する手順を「交渉不能なルール」として設定しました。そして、SQL生成における「事前検証の義務化」です。テーブルやカラムを使用する際は、いきなりクエリを書くのではなく、必ずSystem Promptなどから確認できる情報を取得することです。AIの推論のみで走ってしまうケースがありますが、その場合は存在しないカラムや定義を使用しがちなため、クエリ作成前に必ずナレッジベース等でスキーマ定義を参照するようにガードレールを設けました。
これらの工夫により、AIの思い込みによる無効なクエリ生成を排除し、かつビジネスロジックの適用漏れをシステム的に防ぐ仕組みを構築しています。
課題と解決策
―― プロジェクトを進める中で、苦労したエピソードがあれば教えてください。
小暮:実は、Ver1.0として初期構築したAgentをアイスタイル様にレビューいただいた際、50個もの課題が挙がったんです。正直愕然しました(笑)
押野:そうですね、LLMを業務レベルで使うには、精度向上よりも「動作の再現性をいかに担保するか」が要だと学びました。初期バージョンでは、LLMが「善意」で前処理を省略した結果、全く違う分析結果を返す事態がありましたが、それを機にプロセスの可視化と制御を徹底したことが功を奏したと感じます。
一方で、単にデータが出るだけでなく、出力結果をそのまま営業資料に貼れる形に最適化するなど、現場が迷わず使えるよう実務フローへの組み込みも意識しました。
現在のversionを現場に渡した際に、コンサルタントから「初期と比べると精度が異常に高くなった。データ分析はLLMに任せ、プロンプトを投げている間に、提案内容の骨子を作るというサイクルが出来た」と言われた瞬間はチーム全員が報われた感覚がありました。

成果・効果
―― 取り組みの結果、どのような成果が得られましたか?
押野:具体的な成果は明確に出ています。これまでデータ抽出にかけていた時間を大幅に削減でき、コンサルタント自身でデータを出せるようになりました。社内からは「ここまで自分たちでできるとは思わなかった」という声が多く挙がり、データ分析に対する心理的ハードルが大幅に下がったことは大きな収穫です。
今後の展望
―― 今後の展望をお聞かせください。
押野:実務レベルの手応えは得られましたが、まだ改善余地はあります。今後はLLM出力の再現性と品質を継続的に確認できる仕組みを整え、コンサルタントが日々蓄積している分析ナレッジとの連携を進めたいですね。さらに、構造化データと非構造化データを統合した「真の360度分析」へ踏み込み、組織全体のデータ活用レベルを底上げしていく予定です。
キム:私としても、今後さらにエージェントの精度と効率を高めていきたいですね。現状でも実用レベルには達していますが、より複雑な分析要求にも対応できるよう、プロンプトエンジニアリングの高度化や、AIエージェントの協調動作なども検討しています。
小暮:また、今回の取り組みが他事業部にも展開されつつあるとのことで、横展開しやすい共通基盤として整備を進め、スケーラビリティも確保していく必要があります。

実践者からのアドバイス
―― 最後に、同様の取り組みを検討している企業へアドバイスをお願いします。
押野:LLM活用の成否は、技術よりも「業務の言語化力」で決まると実感しています。業務ルールさえ整理できていれば、LLMは強力な武器になります。逆に言えば、人間側が曖昧なままではAIも曖昧なままです。まずは自分たちの業務を深く理解し、言語化することから始めてみてはいかがでしょうか。
小暮:協業する際は、双方が同じゴールを見据え、オープンなコミュニケーションを取ることが重要です。今回、アイスタイル様が50個もの課題を率直にフィードバックしてくださったことで、プロジェクトは大きく前進しました。遠慮せず、本音で議論できる関係性が成功の鍵だと思います。
キム:技術面では、「完璧を目指さず、段階的に改善する」姿勢が大切です。LLMは発展途上の技術なので、最初から100点を目指すと進まなくなります。まずは小さく始めて、実際に使いながら改善していくアジャイルなアプローチが有効です。また、プロンプトやロジックは「資産」として蓄積されるので、初期投資を惜しまず、しっかりとドキュメント化しておくことをお勧めします。

![]()